Reinforcement Learning — An Introduction | Chapter 1

Today I’m going to start a new series on my
blog where I will be summarizing the
2nd Edition of the most famous popular Reinforcement Learning book,
Reinforcement Learning — An
Introduction
by Richard S. Sutton
and Andrew G. Barto in a
chapter-wise manner. Below is the summary of Chapter 1 and going forward
I will be writing a post of each chapter as I read them.
There are three distinct reasons why I’m undertaking such a project:
- It’s currently the suggested reading material for my Reinforcement Learning course work
- Secondly, while studying the subject matter myself, I felt that doing this will reinforce my understanding as well
- Thirdly, this will act as my notes whenever I wish to come back and revise my understanding (so … mostly being selfish!)
Note: I will be reshuffling the contents of the sub-section based on what I think should be the correct order. If required I will be adding contents from other sources if needed for a more intuitive understanding.
What is Reinforcement Learning?
According to the authors, Reinforcement learning is learning what to do — how to map situations to actions — so that numerical signal which is called a reward can be maximized.
In Reinforcement Learning, an agent is placed in a poorly understood, possibly stochastic, and nonstationary environment. The agent then interacts with the environment at discrete time steps. At every time step, the agent can observe and change the environment’s state through its actions. In addition to state changes, the environment responds to the agent’s actions with a reward, a scalar quantity that represents the immediate utility of taking a given action in a given state. The agent’s objective is to develop a mapping from states to actionscalled a policy that maximizes its long-term return.
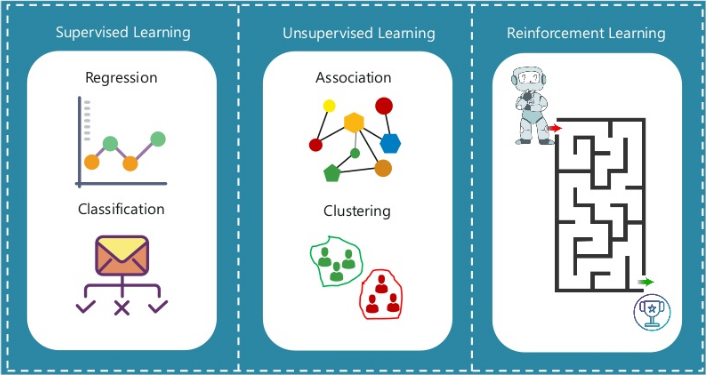
Source: Edureka on Slideshare
One of the major challenges that arise in Reinforcement Learning, and not in other kinds of learning, is the trade-off between exploration and exploitation. Of all the forms of Machine Learning, Reinforcement Learning is the closest to the kind of learning that humans and other animals do. But, if you are looking into a more detail-oriented difference you should refer to this image which is also being referred by David Silver in his Introduction to Reinforcement Learning course with DeepMind.
{kind=link}
Examples of Reinforcement Learning
In order to understand this section of the book, let’s take the below image as an example and try to understand what’s happening (objective) here.
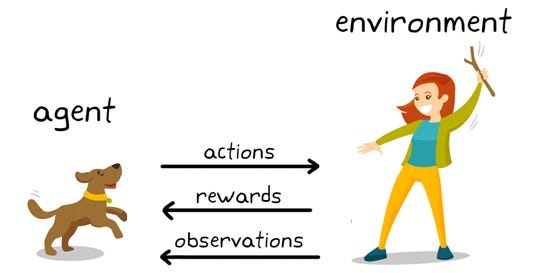
Image Source: https://www.kdnuggets.com/2019/10/mathworks-reinforcement-learning.html
- Objective: To train the agent(Dog) to complete a task within the environment which includes the surroundings of the dog as well as the trainer.
- State: An example of a state could be the Dog standing, and the trainer uses a specific word in for the dog to perform a task.
- Action: When the trainer issues a command, the dog observesand responds by performing the required action.
- Reward:If the action performed by the Dog is closed to the desired behavior the trainer will provide him a reward in the form of food or a toy; otherwise a negative reward or penalty will be given, which is no food or toy.
- Policy: At the beginning of training, the Dog will probably take more random actions like rolling over when the command is given to “sit,” as it is trying to associate specific observations with actions and rewards. This association, or mapping, between observations and actions, is called policy.
So, now that we have a clear understanding based on the above image example that we took, let’s dive into some real-world examples and possible applicationsof Reinforcement Learning.
Note:Do not get overwhelmed by the huge applications of RL in all these amazing fields, these are just to let you know that possibilities are endless, and even greater things are gonna be accomplished as heavy computation starts becoming more easier, according to Moore’s Law.
- The most famous examples are AlphaGo and AlphaGo Zero. AlphaGo, trained with countless human games, already achieved super-human performance by using value network and Monte Carlo tree search (MCTS) in its policy network. Yet, the researchers, later on, thought back and tried a purer RL approach — train it from scratch. The researchers let the new agent, AlphaGo Zero, played with itself and finally beat AlphaGo 100–0.
- Supervised time series (Published by GaTech) models can be used for predicting future sales as well as predicting stock prices. However, these models don’t determine the action to take at a particular stock price. Enter Reinforcement Learning (RL). An RL agent can decide on such a task; whether to hold, buy, or sell. The RL model is evaluated using market benchmark standards in order to ensure that it’s performing optimally. This automation brings consistency into the process, unlike previous methods where analysts would have to make every single decision. IBM for example has a sophisticated reinforcement learning-based platform that has the ability to make financial trades. It computes the reward function based on the loss or profit of every financial transaction.
- In NLP, RL can be used in text summarization, question answering, and machine translation just to mention a few. The authors of thispaper Eunsol Choi, Daniel Hewlett, and Jakob Uszkoreit propose an RL based approach for question answering given long texts. Their method works by first selecting a few sentences from the document that are relevant for answering the question. A slow RNN is then employed to produce answers to the selected sentences.
- In healthcare, patients can receive treatment from policies learned from RL systems. RL is able to find optimal policies using previous experiences without the need for previous information on the mathematical model of biological systems. It makes this approach more applicable than other control-based systems in healthcare.
Elements of Reinforcement Learning
Beyond the agent and the environment that we defined earlier there 4 main subelements of a Reinforcement Learning system. We have already taken peek into reward & policy, but fear not we will be going into a little more detail in this section:
Note:Below is some excerpts that are taken from the book directly, which do not require summarization.
- Policy:is a mapping from perceived states of the environment to actions to be taken when in those states. The policy is the core of a reinforcement learning agent in the sense that it alone is sufficient to determine behavior. It may be stochastic, specifying probabilities for each action.
- Reward Signal:On each time step, the environment sends to the reinforcement learning agent a single number called reward. The agent’s sole objective is to maximize the total reward it receives in the long run. The reward signal thus defines what are the good and the bad signals for the agent. It may be a stochastic function of the state and action.
- Value Function:specifies, roughly, the value of a state is the total amount of reward an agent can expect to accumulate over the future, starting from that state. Whereas rewards determine the immediate, intrinsic desirability of the environmental states, values indicate the long-term desirability of states after taking into account the states that are likely to follow and the rewards available in those states. For example, a state might always yield a low immediate reward but still have a high value because it is regularly followed by other states that yield high rewards, or the reverse could be true.
- Model of the environment:this mimics the behavior of the environment, which allows inferences to be made about how the environment will behave. For example, given a state and an action, the model might predict the resultant next state and next reward. Methods for solving reinforcement learning problems that use models are called model-based methods, as opposed to simpler model-free methods, trial and error learners.
Limitations of Reinforcement Learning
Alex Irpan’s blog post (very detailed … must read!!) is a superb read if you want to understand the many problems with Reinforcement Learning. There are two fundamental difficulties one encounters while solving RL problems:

- The balance of exploration vs. exploitation:Deciding whether to keep following a policy that’s giving a agentnice returns or to take some relatively sub-optimal actions now in case there’s a possibly bigger payoff later? This problem is so hard because there can be no right answer in general — there is always a trade-off.
- Long term credit assignment:Reinforcement Learning agents are basically playing a lottery at every step and trying to figure out what they did to hit a jackpot earlier and got a reward. They are maximizing a single number which is the result of actions over multiple time steps mixed with a good amount of environment randomness. Trying to Figure out which series of actions are actually responsible for the high reward is the problem of credit assignment. One can provide shaping rewards more frequently in order to solve this. As usual, though, if you give an optimization algorithm a weakness, it will exploit it all the way to optimality. If the reward is not well designed it can lead to rewarding hacking (nice blogpost by OpenAI).
Early History of Reinforcement Learning
Note: The below-linked video sums it all, won’t succeed if I try framing it better.
When a configuration is reached for which the action is undetermined, a random choice for the missing data is made and the appropriate entry is made in the description, tentatively, and is applied. When a pain stimulus occurs all tentative entries are cancelled, and when a pleasure stimulus occurs they are all made permanent. (Turing, 1948)
Summary
- Reinforcement learning is a computational approach to understanding and automating goal-directed learning and decision making. It is distinguished from other computational approaches by its emphasis on learning by an agent from direct interaction with its environment, without requiring exemplary supervision or complete models of the environment.
- Reinforcement learning uses the formal framework of Markov Decision Processes to define the interaction between a learning agent and its environment in terms of states, actions, and rewards
Reference
I would suggest going through the reference links for a deeper understanding but would also request my readers to try and avoid getting overwhelmed.
- Study Notes | Reinforcement Learning — An Introduction (really amazing!) — This is for the entire book mostly, and was a trigger for creating a chapter-wise summary to not skip out on the details
- Applications of Reinforcement Learning in Real World
- DeepMind | AlphaGo: The Story So far
- DeepMind | AlphaGo Zero: Starting from scratch
- Research Paper | Deep reinforcement learning for time series: Playing idealized trading games
- Research Paper | Coarse-to-Fine Question Answering for Long Documents
- Research Paper | Challenges of Real-World Reinforcement Learning
- Quora | What are the disadvantages of reinforcement learning and what are the alternatives? by Sridhar Mahadevan, Director of Data Science Lab at Adobe (a really good perspective which is a must-read. Also, check out his other answers)
- Blog Post | Reinforcement Learning Demystified: Markov Decision Processes (Part 1)
- Blog Post | Reinforcement Learning Demystified: Markov Decision Processes (Part 2)