Machine Learning 101 for Dummies like Me

Typing “what is machine learning?” into a Google search opens up a pandora’s box of forums, academic research, and here-say — and the purpose of this article in the 101 for Dummies like Me series is to simplify the definition and understanding of machine learning. In addition to an informed, working definition of machine learning (ML), I aim to provide a succinct overview of the fundamentals of machine learning, the challenges and limitations of getting a machine to ‘think’, some of the issues being tackled today in deep learning (the ‘frontier’ of machine learning), and key takeaways for developing machine learning applications.
In December 2017, DeepMind, the research lab acquired by Google in 2014, introduced AlphaZero, an AI program that could defeat world champions at several board games. Interestingly, AlphaZero received zero instructions from humans on how to play the games (hence the name). Instead, it used machine learning to develop its behavior through experience instead of explicit commands.
Within 24 hours, AlphaZero achieved superhuman performance in chess and defeated the previous world-champion chess program. Shortly after, AlphaZero’s machine-learning algorithm also mastered Shogi (Japanese chess) and the Chinese board game Go, and it defeated its predecessor, AlphaGo, 100 to zero. Machine learning has become popular in recent years and is helping computers solve problems previously thought to be the exclusive domain of human intelligence. And even though it’s still a far shot from the original vision of artificial intelligence, machine learning has gotten us much closer to the ultimate goal of creating thinking machines.
What is Machine Learning?
“Machine Learning is the science of getting computers to learn and act like humans do, and improve their learning over time in autonomous fashion, by feeding them data and information in the form of observations and real-world interactions.”
The above definition encapsulates the ideal objective or ultimate aim of machine learning, as expressed by many researchers in the field. The purpose of this article is to provide its reader with a perspective on how machine learning is defined, and how it works. ML/AI share the same definition in the minds of many, however, there are some distinct differences readers should recognize as well.
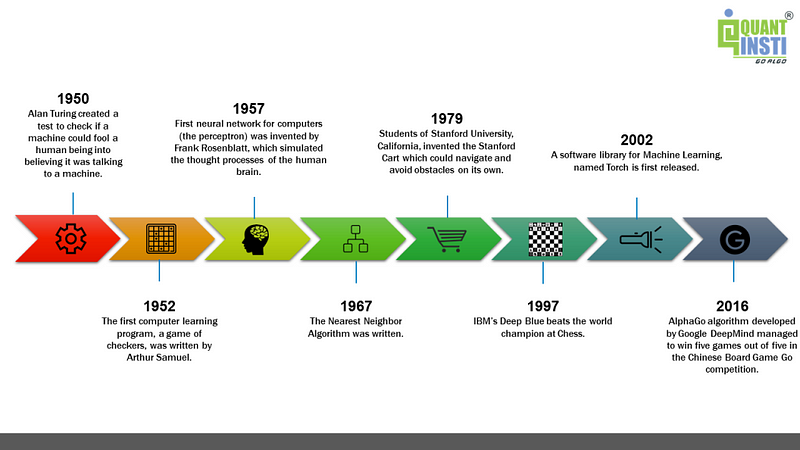
Image Source: https://blog.quantinsti.com/machine-learning-basics/
How is machine learning different from automation?
If you are thinking that machine learning is nothing but a new name of automation — you would be wrong.
- Most of the automation which has happened in the last few decades has been rule-driven automation. For example: automating flows in our mailbox needs us to define the rules. These rules act in the same manner every time. On the other hand, machine learning helps machines learn by past data and change their decisions/performance accordingly.
- Spam detection in our mailboxes is driven by machine learning. Hence, it continues to evolve with time.
- The heavily hyped, self-driving Google car? The essence of machine learning.
- Online recommendation offers, such as those from Amazon and Netflix? Machine learning applications for everyday life.
- Knowing what customers are saying about you on Twitter? Machine learning combined with linguistic rule creation.
The only relation between the two things is that machine learning enables better automation.
How AI & ML differ from each other?
Machine learning may have enjoyed the enormous success of late, but it is just one method for achieving artificial intelligence. At the birth of the field of AI in the 1950s, AI was defined as any machine capable of performing a task that would typically require human intelligence. AI systems will generally demonstrate at least some of the following traits: planning, learning, reasoning, problem-solving, knowledge representation, perception, motion, and manipulation and, to a lesser extent, social intelligence and creativity.
Alongside machine learning, there are various other approaches used to build AI systems, including evolutionary computation, where algorithms undergo random mutations and combinations between generations in an attempt to “evolve” optimal solutions, and expert systems, where computers are programmed with rules that allow them to mimic the behavior of a human expert in a specific domain, for example, an autopilot system flying a plane.
What are the popular misconceptions about machine learning?
Prediction is powerful. Almost as soon as someone realizes what machine learning can do, they want to ask the crystal ball a question:
- What’s going to be the next big programming language?
- Who’s going to win the next election?
- Can you accurately predict our revenue if we create this new product?
But crowding around your data scientist’s desk isn’t going to help you.
- One popular misconception is that people think they have enough data when they don’t. When people say machine learning, a very large segment of predictions are based on existing data. And in order for that to work, you generally have to have a big labeled set of data.
- If you want to predict which product you should recommend to which customer, you need data. Doing that for a product that doesn’t exist yet isn’t going to work. You would need a huge data set, so at least a thousand examples of each of the types of person who bought each product and this increase exponentially with the more features you want to analyze. A feature is something like age, things they clicked on previously, etc. Applying machine learning to your business requires huge data sets that aren’t always accessible, but even if they are, it’s key that that data is in a format that a machine can read.
- People often don’t realize how much machine learning is getting data into a format so that you can feed it into an algorithm. The algorithms are actually usually available pre-baked. In a lot of ways, you need to know how to pick the best linear regression for your data, but you don’t really need to know the intricacies of how it’s programmed. You do need to work the data into a format where each row is a data point, the kind of thing you’d want to pick. For example: If you want your algorithm to look at Customer X, who did or didn’t buy things, you need to assign values for “bought” and “didn’t buy.” This means a lot of cleaning data.
- You actually have to do a lot of work to make all of the different pieces of information you have and knit them together into something you can feed into an algorithm.
Challenges and Limitations of Machine Learning
“Machine learning can’t get something from nothing…what it does is get more from less.” — Dr. Pedro Domingo, University of Washington
- The two biggest, historical (and ongoing) problems in machine learning have involved overfitting (in which the model exhibits bias towards the training data and does not generalize to new data, and/or variance i.e. learns random things when trained on new data) and dimensionality (algorithms with more features work in higher/multiple dimensions, making understanding the data more difficult). Having access to a large enough data set has in some cases also been a primary problem.
- One of the most common mistakes among machine learning beginners is testing training data successfully and having the illusion of success; ML practitioner emphasizes on the importance of keeping some of the data set separate when testing models, and only using that reserved data to test a chosen model, followed by learning on the whole data set.
- When a learning algorithm (i.e. learner) is not working, often the quickest path to success is to feed the machine more data, the availability of which is by now well-known as a primary driver of progress in machine and deep learning algorithms in recent years; however, this can lead to issues with scalability, in which we have more data but time to learn that data remains an issue.
- Machine learning’s lack of reasoning power makes it bad at generalizing its knowledge. For instance, a machine-learning agent that can play Super Mario 3 like a pro won’t dominate another platform game, such as Mega Man, or even another version of Super Mario. It would need to be trained from scratch.
Without the power to extract conceptual knowledge from experience, machine-learning models require tons of training data to perform. Unfortunately, many domains lack sufficient training data or don’t have the funds to acquire more. Deep learning, which is now the prevalent form of machine learning, also suffers from an explainability problem: Neural networks work in complicated ways, and even their creators struggle to follow their decision-making processes. This makes it difficult to use the power of neural networks in settings where there’s a legal requirement to explain AI decisions. Fortunately, efforts are being made to overcome machine learning’s limits. One notable example is a widespread initiative by DARPA, the Department of Defense’s research arm, to create explainable AI models.
Types of Machine Learning & Common Algorithms
Machine learning is not an exact science. It encompasses a broad range of machine learning tools, techniques, and ideas. Here are the most common types of machine learning techniques and algorithms along with a brief summary of how each can be used to solve problems.

- Supervised Learning: Supervised learning is a process like you are learning under someone’s supervision. In supervised learning, the process of an algorithm learning from the training dataset can be thought of as a teacher supervising the learning process. The correct answers are known, the algorithm iteratively makes predictions on the training data and its been corrected by the teacher. The learning phase continues to progress until the algorithm achieves an acceptable level of performance. In supervised learning, data is given with associated labels.

- Unsupervised Learning: In Unsupervised learning, the information used to train is neither classified nor labeled. The goal for unsupervised learning is to model the underlying structure or distribution in the data in order to learn more about the data to form “clusters”, or reducing the data to a small number of important “dimensions”. There are no correct answers and there is no teacher. Algorithms are left on their own to devise, discover and present the interesting structure in the data. Data visualization can also be considered unsupervised learning.
- Reinforcement Learning: It is a learning method that interacts with its environment by producing actions and discovers errors or rewards. It is also known as reward base learning or we can say it works on the principles of feedback. Let’s say you have provided the image of an apple to the machine and then the system identifies it as a ball that is wrong, so you provide the negative feedback to the machine saying that its an apple image. So the machine will learn from the feedback and finally, if it comes across any images of an apple, it will be able to classify it correctly. That’s what reinforcement learning is all about.
Applications of Machine Learning
Of course, all of this technology would be wasted if it wasn’t put to good use. There are many machine learning tools and applications currently in use across every industry. Some of the most common include:
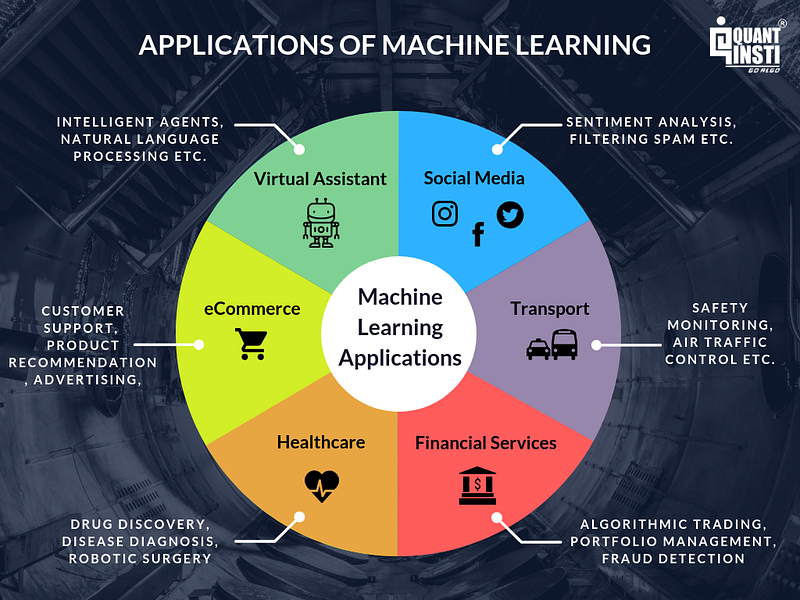
Image Source: https://blog.quantinsti.com/machine-learning-basics/
- Data Security: Malware is a problem that isn’t going to go away anytime soon. The bad news is that thousands of new malware variants are detected every day. The good news is that new malware almost always has the same code as previous versions. This means that machine learning can be used to look for patterns and report anomalies.
- Financial Trading:Patterns and predictions are what help keep the stock market alive and stockbrokers rich. Machine learning algorithms are in use by some of the world’s most prestigious trading companies to predict and execute transactions at high volume and high speed.
- Marketing Personalization:When you understand your customers, you can serve them better. When you serve them better, you sell more. Marketing personalization uses machine learning algorithms to create a truly personalized customer experience that is matched to their previous behavior, likes and dislikes, and location-based data, such as where they prefer to shop.
- Healthcare Industry:Machine learning in healthcare is one such area that is seeing gradual acceptance in the healthcare industry. Google recently developed a machine-learning algorithm to identify cancerous tumors in mammograms, and researchers at Stanford University are using deep learning to identify skin cancer. Machine Learning (ML) is already lending a hand in diverse situations in healthcare. ML in healthcare helps to analyze thousands of different data points and suggest outcomes, provide timely risk scores, precise resource allocation, and has many other applications.
- Retail Industry:Businesses organizations that are in the retail industry or e-commerce companies have been using advanced machine learning applications including Recommendation systems, Chat-bot applications, Predictive Analytics systems, etc. to innovate and enhance their business processes. A number of big Retail and E-commerce industries like Walmart, Amazon, Alibaba, Flipkart have successfully incorporated AI and Machine Learning technologies across their entire sales cycles from logistics to sales to post-sales services, thus improve results as well as business processes.
Human Biases
Although data and computational analysis may make us think that we are receiving objective information, this is not the case; being based on data does not mean that machine learning outputs are neutral. Human bias plays a role in how data is collected, organized, and ultimately in the algorithms that determine how machine learning will interact with that data. If, for example, people are providing images for “fish” as data to train an algorithm, and these people overwhelmingly select images of goldfish, a computer may not classify a shark as a fish. This would create a bias against sharks as fish, and sharks would not be counted as fish.
When using historical photographs of scientists as training data, a computer may not properly classify scientists who are also people of color or women. In fact, recent peer-reviewed research has indicated that AI and machine learning programs exhibit human-like biases that include race and gender prejudices. See, for example, “Semantics derived automatically from language corpora contain human-like biases” and “Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints” [PDF]. As machine learning is increasingly leveraged in business, uncaught biases can perpetuate systemic issues that may prevent people from qualifying for loans, from being shown ads for high-paying job opportunities, or from receiving same-day delivery options.
Because human bias can negatively impact others, it is extremely important to be aware of it and to also work towards eliminating it as much as possible. One way to work towards achieving this is by ensuring that there are diverse people working on a project and that diverse people are testing and reviewing it. Others have called for regulatory third parties to monitor and audit algorithms, building alternative systems that can detect biases and ethics reviews as part of the data science project planning. Raising awareness about biases, being mindful of our own unconscious biases, and structuring equity in our machine learning projects and pipelines can work to combat bias in this field.
Conclusion
While machine learning algorithms have been around for decades, they’ve attained new popularity as artificial intelligence (AI) has grown in prominence. Deep learning models in particular power today’s most advanced AI applications.
Machine learning platforms are among enterprise technology’s most competitive realms, with most major vendors, including Amazon, Google, Microsoft, IBM, and others, racing to sign customers up for platform services that cover the spectrum of machine learning activities, including data collection, data preparation, model building, training and application deployment. As machine learning continues to increase in importance to business operations and AI becomes ever more practical in enterprise settings, the machine learning platform wars will only intensify.
Continued research into deep learning and AI is increasingly focused on developing more general applications. Today’s AI models require extensive training in order to produce an algorithm that is highly optimized to perform one task. But some researchers are exploring ways to make models more flexible and able to apply context learned from one task to future, different tasks.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Books
1.Pattern Recognition and Machine Learning,
2006.
2.Deep Learning, 2016.
3.Reinforcement Learning: An Introduction,
2nd edition, 2018.
4.Data Mining: Practical Machine Learning Tools and
Techniques, 4th edition, 2016.
5.The Elements of Statistical Learning: Data Mining, Inference, and
Prediction, 2nd edition, 2016.
6.Machine Learning: A Probabilistic
Perspective, 2012.
7.Machine Learning, 1997.
8.The Nature of Statistical Learning Theory,
1995.
9.Foundations of Machine Learning, 2nd
edition, 2018.
10.Artificial Intelligence: A Modern
Approach, 3rd edition, 2015.
Papers
1.Revisiting Self-Supervised Visual Representation
Learning, 2019.
2.Active Learning Literature
Survey, 2009.